


引言 #
梳理一下 GEMINI-CLI 中的配置和具体的效果
顺便梳理 GEMINI-CLI 中的参数对于 cli 模式和 a2a-server 模式的支持范围
参数来源具体参考,本文梳理比较重要或者比较有迷惑性的一些参数来说明,像是 general.preferredEditor (cli 模式下的)、general.previewFeatures 等等这种参数就不进行额外说明了。
同时本文重点区分了一下当前 a2a-server 和 cli 模式之间的 gap,以此参数相关的功能和 PR。
general #
checkpointing #
参数设置:general.checkpointing.enabled
Github PR: https://github.com/google-gemini/gemini-cli/pull/934
是否支持 cli/a2a-server:都支持
功能描述:
支持针对对话历史的 checkpoint 存储,只会存储 write、replace 等写操作相关工具中状态是 awaiting_approval的 tool call。
这个机制是为了在用户批准一个修改文件的操作(如写入或替换)之前,自动保存当前的上下文和 Git 快照。这样如果操作出了问题,可以利用这个 JSON 文件和 Git hash 进行回滚或恢复。普通的只读操作(如 read_file)或者已经执行过的操作不会触发这个保存逻辑。
checkpointing 会存储在下面这个目录下:
${homedir}/.gemini/tmp/${projectPathHash}/checkpoints
每一个 tool call 会单独存储为文件,并会记录当前的 git commit hash,具体的文件格式如下:
${homedir}/.gemini/tmp/${projectPathHash}/checkpoints/${timestamp}-${tool.args.file_path}-${toolName}.json
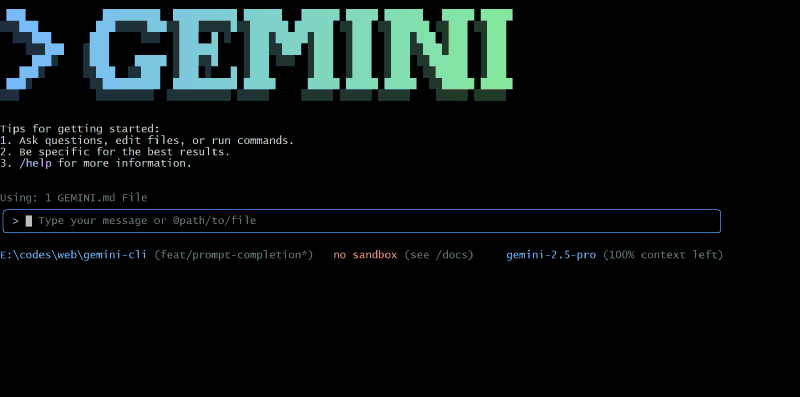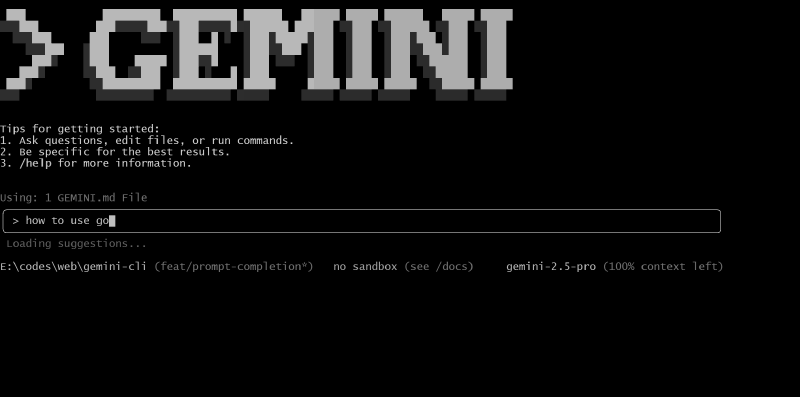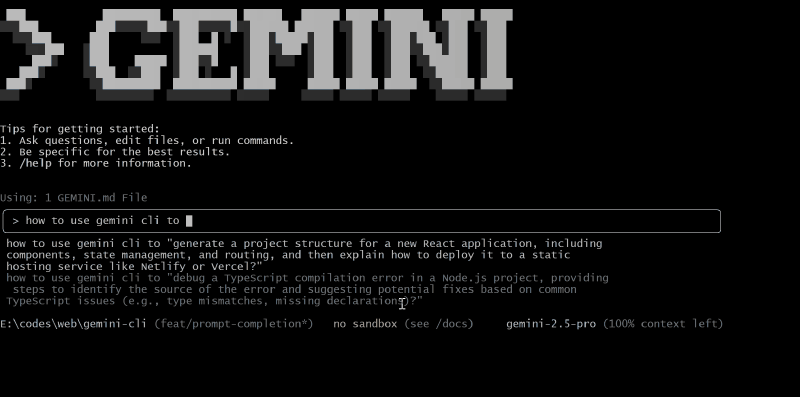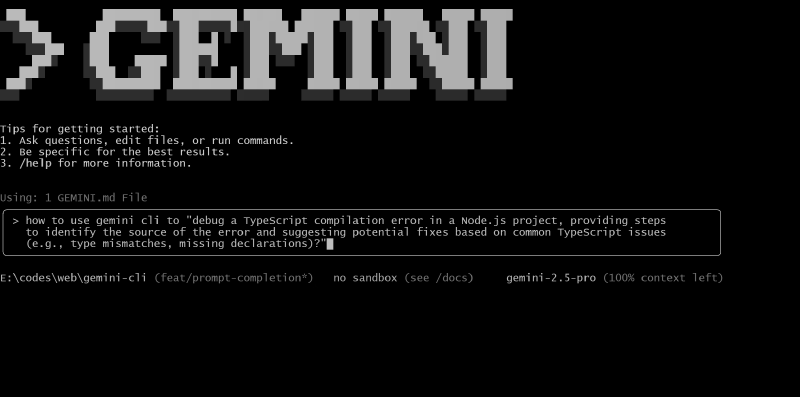
enablePromptCompletion #
参数设置:
Github PR: https://github.com/google-gemini/gemini-cli/pull/4691
是否支持 cli/a2a-server:仅支持 cli,不支持 a2a-server
**功能描述:**使用 gemini-flash-2.5:nothinking 模型实时 自动补全 prompt ,类似于 Google 提供的 Search Suggestions 或 GitHub Copilot 提供的 Code Completion 。
sessionRetention #
参数设置:
general.sessionRetention.enabledgeneral.sessionRetention.maxAgegeneral.sessionRetention.maxCountgeneral.sessionRetention.minRetention
Github PR: https://github.com/google-gemini/gemini-cli/pull/7662 / https://github.com/google-gemini/gemini-cli/pull/4401
是否支持 cli/a2a-server:仅支持 cli,不支持 a2a-server
功能描述:
用于管理 cli 模式下,存在磁盘中的会话。通过配置 maxAge 和 maxCount 分别可以设置磁盘中会话记录的保存最大时长和最大数量。还支持设置 minRetention 设置一个最小保留时间,防止 maxAge 或者 maxCount 设置过短。
privacy #
usageStatisticsEnabled #
参数设置:privacy.usageStatisticsEnabled
Github PR: https://github.com/google-gemini/gemini-cli/pull/6217
是否支持 cli/a2a-server:仅支持 cli,a2a-server 默认开启不支持配置
功能描述:
表明用户是否允许 Gemini CLI 收集匿名的使用数据,类似隐私开关。
model #
name #
参数设置:model.name
是否支持 cli/a2a-server:都支持,a2a-server 通过环境变量支持
功能描述:
主 Agent 的模型名,默认的模型名
maxSessionTurns #
参数设置:model.maxSessionTurns
Github PR: https://github.com/google-gemini/gemini-cli/pull/3507
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
一整个 session 的对话轮数的最大值,旨在防止无限循环。默认是 -1 即无限制。
summarizeToolOutput #
参数设置:model.summarizeToolOutput
Github PR: https://github.com/google-gemini/gemini-cli/pull/4140
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
用于控制工具输出的长度,必要的时候进行总结和摘要。
目前仅能支持 run_shell_command 工具的总结,通过在packages/core/src/config/defaultModelConfigs.ts 文件中的 summarizer-shell 配置的gemini-2.5-flash-lite 模型进行总结。
本参数可以配置为
{
"summarizeToolOutput": {
"run_shell_command": {
"tokenBudget": 2000
}
}
}
compressionThreshold #
参数设置:model.compressionThreshold
Github PR: https://github.com/google-gemini/gemini-cli/pull/12001 / https://github.com/google-gemini/gemini-cli/pull/12317
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
用于触发上下文压缩的阈值,默认 0.5。
假设模型最大输入 token 是 128k,那么默认情况下,在输入 token (历史对话) 到达 64k token 的时候会自动触发上下文压缩。
上下文压缩时使用的模型也是在 packages/core/src/config/defaultModelConfigs.ts 文件中的 chat-compression-* 配置的。
packages/core/src/core/tokenLimits.ts 中配置的,这里只设置了 gemini 模型的最大 token,其他模型默认全都是 1048576 token,也就是在 524288 (524k) token 的时候会开启上下文压缩。
skipNextSpeakerCheck #
参数设置:model.skipNextSpeakerCheck
Github PR: https://github.com/google-gemini/gemini-cli/pull/5257
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
用于判断模型是否需要进行下一步。
模型在执行的过程中可能会偶尔未执行完成便结束了,为了防止这类 case ,大概有以下几种规则判断
- 如果最后一条 message 是 tool call (function),那么会添加一条
The last message was a function response, so the model should speak next.记录并继续执行 - 如果最后一条 message 没有 content,那么会添加一条
The last message was a filler model message with no content (nothing for user to act on), model should speak next.记录并继续执行 - 最后会通过在
packages/core/src/config/defaultModelConfigs.ts文件中next-speaker-checker配置对应的模型来判断要不要继续执行,默认是gemini-2.5-flash-base
modelConfigs (重要!!!) #
aliases #
参数设置:modelConfigs.aliases
Github PR: https://github.com/google-gemini/gemini-cli/pull/12556
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
默认的配置我们可以看 packages/core/src/config/defaultModelConfigs.ts 文件。
json 贴在下面了,方便起见可以看表格
| key (场景) | 模型 | 配置继承 | 参数 | 备注 |
|---|---|---|---|---|
| base | temperature: 0; topP: 1 | 基础配置 | ||
| chat-base | base | temperature: 1; topP: 0.95; topK: 64; | 基础配置 | |
| chat-base-2.5 | chat-base | thinkingBudget: 8192 | 基础配置 | |
| chat-base-3 | chat-base | thinkingLevel: HIGH | 基础配置 | |
| gemini-3-pro-preview | gemini-3-pro-preview | chat-base-3 | chat | |
| gemini-2.5-flash | gemini-2.5-flash | chat-base-2.5 | chat | |
| gemini-2.5-flash-lite | gemini-2.5-flash-lite | chat-base-2.5 | chat | |
| gemini-2.5-flash-base | gemini-2.5-flash-base | base | 基础配置 | |
| classifier | gemini-2.5-flash-lite | base | maxOutputTokens: 1024; thinkingBudget: 512 | 分类器,根据任务复杂度选择 pro / flash |
| prompt-completion | gemini-2.5-flash-lite | base | temperature: 0.3; maxOutputTokens: 16000; thinkingBudget: 0 | prompt 实时补全 |
| edit-corrector | gemini-2.5-flash-lite | base | thinkingBudget: 0 | edit tool 本质是一个替换工具,当失败的时候调用 edit-corrector 修复字符串替换前后的采纳数 |
| summarizer-shell | gemini-2.5-flash-lite | base | maxOutputToken: 2000 | 总结 shell 工具的结果 |
| web-search | gemini-2.5-flash-base | 网页搜索 | ||
| web-fetch | gemini-2.5-flash-base | 使用 prompt 获取 url 内容并回答(公开链接) | ||
| web-fetch-fallback | gemini-2.5-flash-base | 本地执行 fetch url 并让模型总结摘要 (私有链接) | ||
| loop-detection | gemini-2.5-flash-base | 循环检测 | ||
| loop-detection-double-check | gemini-2.5-pro | base | 循环检测二次检查 | |
| llm-edit-fixer | gemini-2.5-flash-base | smart-edit 工具失败时,尝试用 llm-edit-fixer 修复。smart-edit 同样是一个替换工具 | ||
| next-speaker-checker | gemini-2.5-flash-base | 是否继续执行 | ||
| chat-compression-3-pro | gemini-3-pro-previe | 上下文压缩 | ||
| chat-compression-2.5-pro | gemini-2.5-pro | 上下文压缩 | ||
| chat-compression-2.5-flash | gemini-2.5-flash | 上下文压缩 | ||
| chat-compression-2.5-flash-lite | gemini-2.5-flash-lite | 上下文压缩 | ||
| chat-compression-default | gemini-2.5-pro | 上下文压缩 |
{
"base": {
"modelConfig": {
"generateContentConfig": {
"temperature": 0,
"topP": 1
}
}
},
"chat-base": {
"extends": "base",
"modelConfig": {
"generateContentConfig": {
"thinkingConfig": {
"includeThoughts": true
},
"temperature": 1,
"topP": 0.95,
"topK": 64
}
}
},
"chat-base-2.5": {
"extends": "chat-base",
"modelConfig": {
"generateContentConfig": {
"thinkingConfig": {
"thinkingBudget": 8192
}
}
}
},
"chat-base-3": {
"extends": "chat-base",
"modelConfig": {
"generateContentConfig": {
"thinkingConfig": {
"thinkingLevel": "HIGH"
}
}
}
},
"gemini-3-pro-preview": {
"extends": "chat-base-3",
"modelConfig": {
"model": "gemini-3-pro-preview"
}
},
"gemini-2.5-pro": {
"extends": "chat-base-2.5",
"modelConfig": {
"model": "gemini-2.5-pro"
}
},
"gemini-2.5-flash": {
"extends": "chat-base-2.5",
"modelConfig": {
"model": "gemini-2.5-flash"
}
},
"gemini-2.5-flash-lite": {
"extends": "chat-base-2.5",
"modelConfig": {
"model": "gemini-2.5-flash-lite"
}
},
"gemini-2.5-flash-base": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash"
}
},
"classifier": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"maxOutputTokens": 1024,
"thinkingConfig": {
"thinkingBudget": 512
}
}
}
},
"prompt-completion": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"temperature": 0.3,
"maxOutputTokens": 16000,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}
},
"edit-corrector": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"thinkingConfig": {
"thinkingBudget": 0
}
}
}
},
"summarizer-default": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"maxOutputTokens": 2000
}
}
},
"summarizer-shell": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"maxOutputTokens": 2000
}
}
},
"web-search": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {
"generateContentConfig": {
"tools": [
{
"googleSearch": {}
}
]
}
}
},
"web-fetch": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {
"generateContentConfig": {
"tools": [
{
"urlContext": {}
}
]
}
}
},
"web-fetch-fallback": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {}
},
"loop-detection": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {}
},
"loop-detection-double-check": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-pro"
}
},
"llm-edit-fixer": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {}
},
"next-speaker-checker": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {}
},
"chat-compression-3-pro": {
"modelConfig": {
"model": "gemini-3-pro-preview"
}
},
"chat-compression-2.5-pro": {
"modelConfig": {
"model": "gemini-2.5-pro"
}
},
"chat-compression-2.5-flash": {
"modelConfig": {
"model": "gemini-2.5-flash"
}
},
"chat-compression-2.5-flash-lite": {
"modelConfig": {
"model": "gemini-2.5-flash-lite"
}
},
"chat-compression-default": {
"modelConfig": {
"model": "gemini-2.5-pro"
}
}
}
overrides #
参数设置:modelConfigs.overrides
Github PR: https://github.com/google-gemini/gemini-cli/pull/12556
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
支持特定场景,直接覆盖某个模型的配置,忽略 aliases 中的配置,强制使用 overrides。好处是需要批量改的时候这里只用改一个。
overrideScope 为 core 时默认都走这个配置,否则 overrideScope 需要和上面的 key 匹配。
[
{
"match": {
"model": "chat-base",
"overrideScope": "core"
},
"modelConfig": {
"generateContentConfig": {
"temperature": 0.5
}
}
},
{
"match": {
"model": "chat-base",
"overrideScope": "loop-detection"
},
"modelConfig": {
"generateContentConfig": {
"temperature": 0
}
}
}
]
customAliases #
参数设置:modelConfigs.customAliases
Github PR: https://github.com/google-gemini/gemini-cli/pull/13546
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
支持自定义 aliases,只是优先级比 aliases 更高,本身感觉没啥。
context #
fileName #
参数设置:context.fileName
Github PR: https://github.com/google-gemini/gemini-cli/pull/1001
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
用来配置上下文记忆的文件列表。
includeDirectories #
参数设置:context.includeDirectories
Github PR: https://github.com/google-gemini/gemini-cli/pull/5354
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
模型可以看到的除了 workspace 工作区,其他的目录,可以理解为支持多 workspace。
loadMemoryFromIncludeDirectories #
参数设置:context.includeDirectories
Github PR: https://github.com/google-gemini/gemini-cli/pull/5354
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
支持加载不同 workspace 目录的 .gemini 中的GEMINI.md 文件。
fileFiltering #
参数设置:
context.fileFiltering.respectGitIgnorecontext.fileFiltering.respectGeminiIgnorecontext.fileFiltering.enableRecursiveFileSearchcontext.fileFiltering.disableFuzzySearch
Github PR: https://github.com/google-gemini/gemini-cli/pull/1290 / https://github.com/google-gemini/gemini-cli/pull/3727 / https://github.com/google-gemini/gemini-cli/pull/6087 /
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
文件搜索的时候是否过滤 .gitignore 和 .geminiignore ,是否支持递归检索,是否禁用模糊检索。
respectGitIgnore 和 respectGeminiIgnore 之后启动可能会比较慢!
tools #
sandbox #
参数设置:tools.sandbox
Github PR: https://github.com/google-gemini/gemini-cli/pull/1154
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不可用
功能描述:
是否开启沙箱或者沙箱的镜像。
shell #
参数设置:
tools.shell.enableInteractiveShelltools.shell.pager(忽略)tools.shell.showColor(忽略)tools.shell.inactivityTimeout
Github PR: https://github.com/google-gemini/gemini-cli/pull/10661 / https://github.com/google-gemini/gemini-cli/pull/13531
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
enableInteractiveShell 决定用哪种 shell 模式,如果开启则使用 node-pty,不开启使用 child_process.spawn 或 child_process.exec
inactivityTimeout 为 shell 命令无输出的最长时间,默认 5 分钟。
autoAccept #
参数设置:tools.autoAccept
Github PR: https://github.com/google-gemini/gemini-cli/pull/6665
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置,官方也注释了 server 端 agent 可能不需要关联沙盒
功能描述:
自动接受,分为三种模式:Default、AUTO_EDIT、YOLO 。
a2a-server 目前没支持配置 AUTO_EDIT。
core #
参数设置: tools.core
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
用于限制内置的 tools
allowed #
参数设置:tools.allowed
Github PR: https://github.com/google-gemini/gemini-cli/pull/6453
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
允许跳过用户确认的工具集,针对 shell 命令可以细粒度控制是否确认具体的 command,如:[“run_shell_command(git)”, “run_shell_command(npm test)”]
exclude #
参数设置:tools.exclude
Github PR: https://github.com/google-gemini/gemini-cli/pull/12728
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
用于排除特定工具。
enableToolOutputTruncation #
参数设置:tools.enableToolOutputTruncation
Github PR: https://github.com/google-gemini/gemini-cli/pull/8039
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
run_shell_command 工具
对 tool 的输出进行截断,根据字符数截断,截断的阈值是 truncateToolOutputThreshold 参数和 模型的 limit token * 4 减去已经消耗的 token。这里默认 1 个 token 大约等于 4 个字符。
Math.min(
// Estimate remaining context window in characters (1 token ~= 4 chars).
4 *
(tokenLimit(this.model) - uiTelemetryService.getLastPromptTokenCount()),
this.truncateToolOutputThreshold,
)
truncateToolOutputThreshold #
参数设置:tools.truncateToolOutputThreshold
Github PR: https://github.com/google-gemini/gemini-cli/pull/8039
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
run_shell_command 工具
截断 tool 输出的字符数阈值。
truncateToolOutputLines #
参数设置:tools.truncateToolOutputLines
Github PR: https://github.com/google-gemini/gemini-cli/pull/8039
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
run_shell_command 工具
截断 tool 输出的行数阈值。
enableMessageBusIntegration #
参数设置:tools.enableMessageBusIntegration
Github PR: https://github.com/google-gemini/gemini-cli/issues/7231
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
是否启用消息总线集成。这个消息总线 (MessageBus) 大概有如下几个作用:
- 可以作为工具执行总体的上下文,工具执行的时候除了入参就只有这个消息总线了,如果想找一个 context 这个是比较合适的
- 消息总线中集成了策略引擎,进而集成一些策略规则
- 如是否允许执行、拒绝执行或者需要询问用户
- safety 安全相关的检查规则
- hook 相关的检查规则
enableHooks #
参数设置:tools.enableHooks
Github PR: https://github.com/google-gemini/gemini-cli/issues/9097
是否支持 cli/a2a-server:仅支持 cli,hook 的注册和执行仅支持 cli
功能描述:
enableMessageBusIntegration
是否支持在消息总线中检测 hook 行为。
security #
blockGitExtensions #
参数设置:security.blockGitExtensions
Github PR: https://github.com/google-gemini/gemini-cli/pull/12838
是否支持 cli/a2a-server:仅支持 cli,a2a-server 不支持配置
功能描述:
阻止从 git 和 github-release 安装和加载扩展。默认有四种类型支持 git、github-release、local 和
link。这里的 Extensions 指的是在 ~/.gemini/extensions 的 gemini-cli 的扩展,可以是 Mcp 可以是 hook 可以是 memory 上下文等等。
后记 #
其他还有一些参数像是 hooks 、advanced、mcpServers、telemetry 等等这里就不具体关注了。感兴趣的话可以直接去看 gemini-cli 的官方文档