


Introduction #
Overview of the configuration and specific effects in GEMINI-CLI.
This also outlines the support scope of GEMINI-CLI parameters for CLI mode and A2A-server mode.
The parameters are referenced from specific sources. This article focuses on some important or confusing parameters, such as general.preferredEditor (in CLI mode), general.previewFeatures, etc., which will not be explained separately.
At the same time, this article highlights the gap between current A2A-server and CLI modes, referencing related features and PRs.
general #
checkpointing #
Parameter Setting: general.checkpointing.enabled
Github PR: https://github.com/google-gemini/gemini-cli/pull/934
Supported in CLI/A2A-Server: Both supported
Function Description:
Supports checkpoint storage for conversation history. It only stores tool calls with awaiting_approval status in write operations like write, replace, etc.
This mechanism is designed to automatically save the current context and Git snapshot before the user approves a file modification operation (such as write or replace). This way, if the operation goes wrong, you can use this JSON file and Git hash to rollback or restore. Ordinary read-only operations (such as read_file) or operations that have already been executed will not trigger this save logic.
Checkpoints will be stored in the following directory:
${homedir}/.gemini/tmp/${projectPathHash}/checkpoints
Each tool call will be stored as a separate file, and the current git commit hash will be recorded. The specific file format is as follows:
${homedir}/.gemini/tmp/${projectPathHash}/checkpoints/${timestamp}-${tool.args.file_path}-${toolName}.json
enablePromptCompletion #
Parameter Setting: general.enablePromptCompletion
Github PR: https://github.com/google-gemini/gemini-cli/pull/4691
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description: Uses the gemini-flash-2.5:nothinking model for real-time automatic prompt completion, similar to Search Suggestions provided by Google or Code Completion provided by GitHub Copilot.
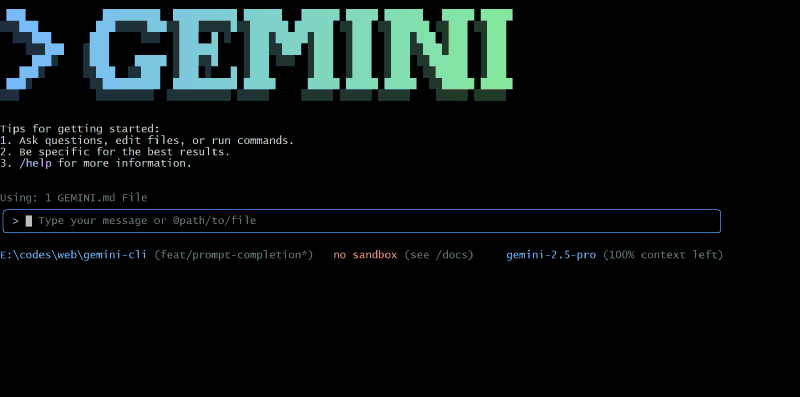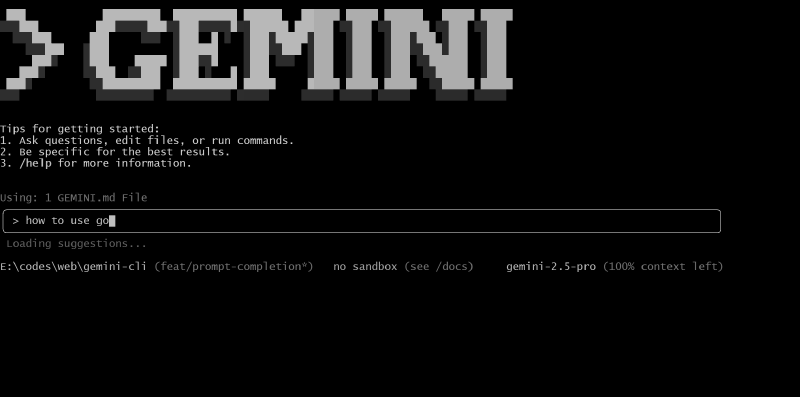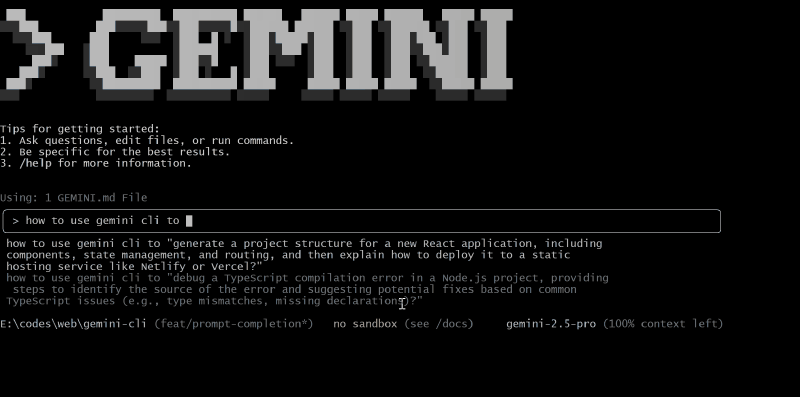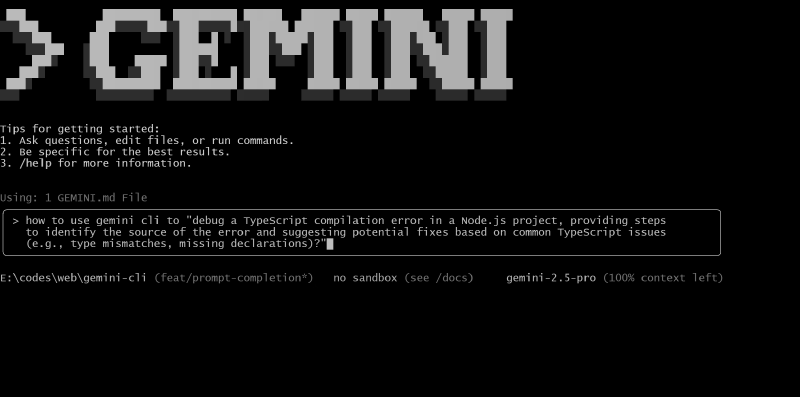
sessionRetention #
Parameter Setting:
general.sessionRetention.enabledgeneral.sessionRetention.maxAgegeneral.sessionRetention.maxCountgeneral.sessionRetention.minRetention
Github PR: https://github.com/google-gemini/gemini-cli/pull/7662 / https://github.com/google-gemini/gemini-cli/pull/4401
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Used to manage sessions stored on disk in CLI mode. By configuring maxAge and maxCount, you can set the maximum duration and maximum number of session records saved on disk, respectively. It also supports setting minRetention to set a minimum retention time to prevent maxAge or maxCount from being set too short.
privacy #
usageStatisticsEnabled #
Parameter Setting: privacy.usageStatisticsEnabled
Github PR: https://github.com/google-gemini/gemini-cli/pull/6217
Supported in CLI/A2A-Server: Only CLI supported (A2A-server enabled by default, not configurable)
Function Description:
Indicates whether the user allows Gemini CLI to collect anonymous usage data, similar to a privacy switch.
model #
name #
Parameter Setting: model.name
Supported in CLI/A2A-Server: Both supported (A2A-server supported via environment variables)
Function Description:
The model name of the main Agent, the default model name.
maxSessionTurns #
Parameter Setting: model.maxSessionTurns
Github PR: https://github.com/google-gemini/gemini-cli/pull/3507
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
The maximum number of conversation turns in a session, designed to prevent infinite loops. Default is -1, which means unlimited.
summarizeToolOutput #
Parameter Setting: model.summarizeToolOutput
Github PR: https://github.com/google-gemini/gemini-cli/pull/4140
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Used to control the length of tool output, summarizing and digesting when necessary.
Currently only supports summarization for the run_shell_command tool, using the gemini-2.5-flash-lite model configured in summarizer-shell in the packages/core/src/config/defaultModelConfigs.ts file.
This parameter can be configured as:
{
"summarizeToolOutput": {
"run_shell_command": {
"tokenBudget": 2000
}
}
}
compressionThreshold #
Parameter Setting: model.compressionThreshold
Github PR: https://github.com/google-gemini/gemini-cli/pull/12001 / https://github.com/google-gemini/gemini-cli/pull/12317
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
The threshold for triggering context compression, default is 0.5.
Assuming the model’s maximum input token is 128k, context compression will be automatically triggered when the input tokens (history conversation) reach 64k tokens by default.
The model used for context compression is also configured in chat-compression-* in the packages/core/src/config/defaultModelConfigs.ts file.
packages/core/src/core/tokenLimits.ts. Here, only the maximum token for the gemini model is set. All other models default to 1048576 tokens, meaning context compression will start at 524288 (524k) tokens.
skipNextSpeakerCheck #
Parameter Setting: model.skipNextSpeakerCheck
Github PR: https://github.com/google-gemini/gemini-cli/pull/5257
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Used to determine whether the model needs to proceed to the next step.
The model might occasionally end before execution is complete. To prevent such cases, there are several judgment rules:
- If the last message is a tool call (function), a record
The last message was a function response, so the model should speak next.will be added and execution will continue. - If the last message has no content, a record
The last message was a filler model message with no content (nothing for user to act on), model should speak next.will be added and execution will continue. - Finally, the model corresponding to
next-speaker-checkerconfigured in thepackages/core/src/config/defaultModelConfigs.tsfile will be used to judge whether to continue execution. The default isgemini-2.5-flash-base.
modelConfigs (Important!!!) #
aliases #
Parameter Setting: modelConfigs.aliases
Github PR: https://github.com/google-gemini/gemini-cli/pull/12556
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
For default configurations, we can look at the packages/core/src/config/defaultModelConfigs.ts file.
The JSON is pasted below. For convenience, you can refer to the table:
| key (Scenario) | Model | Config Extends | Parameters | Remarks |
|---|---|---|---|---|
| base | temperature: 0; topP: 1 | Base configuration | ||
| chat-base | base | temperature: 1; topP: 0.95; topK: 64; | Base configuration | |
| chat-base-2.5 | chat-base | thinkingBudget: 8192 | Base configuration | |
| chat-base-3 | chat-base | thinkingLevel: HIGH | Base configuration | |
| gemini-3-pro-preview | gemini-3-pro-preview | chat-base-3 | chat | |
| gemini-2.5-flash | gemini-2.5-flash | chat-base-2.5 | chat | |
| gemini-2.5-flash-lite | gemini-2.5-flash-lite | chat-base-2.5 | chat | |
| gemini-2.5-flash-base | gemini-2.5-flash-base | base | Base configuration | |
| classifier | gemini-2.5-flash-lite | base | maxOutputTokens: 1024; thinkingBudget: 512 | Classifier, chooses pro / flash based on task complexity |
| prompt-completion | gemini-2.5-flash-lite | base | temperature: 0.3; maxOutputTokens: 16000; thinkingBudget: 0 | Prompt real-time completion |
| edit-corrector | gemini-2.5-flash-lite | base | thinkingBudget: 0 | edit tool is essentially a replacement tool. When it fails, edit-corrector is called to fix the applied replacements. |
| summarizer-shell | gemini-2.5-flash-lite | base | maxOutputToken: 2000 | Summarizes shell tool results |
| web-search | gemini-2.5-flash-base | Web search | ||
| web-fetch | gemini-2.5-flash-base | Uses prompt to fetch url content and answer (public links) | ||
| web-fetch-fallback | gemini-2.5-flash-base | Locally executes fetch url and lets model summarize (private links) | ||
| loop-detection | gemini-2.5-flash-base | Loop detection | ||
| loop-detection-double-check | gemini-2.5-pro | base | Loop detection double check | |
| llm-edit-fixer | gemini-2.5-flash-base | When smart-edit tool fails, attempts to use llm-edit-fixer to fix. smart-edit is also a replacement tool. | ||
| next-speaker-checker | gemini-2.5-flash-base | Checks if execution should continue | ||
| chat-compression-3-pro | gemini-3-pro-preview | Context compression | ||
| chat-compression-2.5-pro | gemini-2.5-pro | Context compression | ||
| chat-compression-2.5-flash | gemini-2.5-flash | Context compression | ||
| chat-compression-2.5-flash-lite | gemini-2.5-flash-lite | Context compression | ||
| chat-compression-default | gemini-2.5-pro | Context compression |
{
"base": {
"modelConfig": {
"generateContentConfig": {
"temperature": 0,
"topP": 1
}
}
},
"chat-base": {
"extends": "base",
"modelConfig": {
"generateContentConfig": {
"thinkingConfig": {
"includeThoughts": true
},
"temperature": 1,
"topP": 0.95,
"topK": 64
}
}
},
"chat-base-2.5": {
"extends": "chat-base",
"modelConfig": {
"generateContentConfig": {
"thinkingConfig": {
"thinkingBudget": 8192
}
}
}
},
"chat-base-3": {
"extends": "chat-base",
"modelConfig": {
"generateContentConfig": {
"thinkingConfig": {
"thinkingLevel": "HIGH"
}
}
}
},
"gemini-3-pro-preview": {
"extends": "chat-base-3",
"modelConfig": {
"model": "gemini-3-pro-preview"
}
},
"gemini-2.5-pro": {
"extends": "chat-base-2.5",
"modelConfig": {
"model": "gemini-2.5-pro"
}
},
"gemini-2.5-flash": {
"extends": "chat-base-2.5",
"modelConfig": {
"model": "gemini-2.5-flash"
}
},
"gemini-2.5-flash-lite": {
"extends": "chat-base-2.5",
"modelConfig": {
"model": "gemini-2.5-flash-lite"
}
},
"gemini-2.5-flash-base": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash"
}
},
"classifier": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"maxOutputTokens": 1024,
"thinkingConfig": {
"thinkingBudget": 512
}
}
}
},
"prompt-completion": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"temperature": 0.3,
"maxOutputTokens": 16000,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}
},
"edit-corrector": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"thinkingConfig": {
"thinkingBudget": 0
}
}
}
},
"summarizer-default": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"maxOutputTokens": 2000
}
}
},
"summarizer-shell": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-flash-lite",
"generateContentConfig": {
"maxOutputTokens": 2000
}
}
},
"web-search": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {
"generateContentConfig": {
"tools": [
{
"googleSearch": {}
}
]
}
}
},
"web-fetch": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {
"generateContentConfig": {
"tools": [
{
"urlContext": {}
}
]
}
}
},
"web-fetch-fallback": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {}
},
"loop-detection": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {}
},
"loop-detection-double-check": {
"extends": "base",
"modelConfig": {
"model": "gemini-2.5-pro"
}
},
"llm-edit-fixer": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {}
},
"next-speaker-checker": {
"extends": "gemini-2.5-flash-base",
"modelConfig": {}
},
"chat-compression-3-pro": {
"modelConfig": {
"model": "gemini-3-pro-preview"
}
},
"chat-compression-2.5-pro": {
"modelConfig": {
"model": "gemini-2.5-pro"
}
},
"chat-compression-2.5-flash": {
"modelConfig": {
"model": "gemini-2.5-flash"
}
},
"chat-compression-2.5-flash-lite": {
"modelConfig": {
"model": "gemini-2.5-flash-lite"
}
},
"chat-compression-default": {
"modelConfig": {
"model": "gemini-2.5-pro"
}
}
}
overrides #
Parameter Setting: modelConfigs.overrides
Github PR: https://github.com/google-gemini/gemini-cli/pull/12556
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Supports specific scenarios by directly overriding a model’s configuration, ignoring configurations in aliases, and forcing the use of overrides. The benefit is that when batch changes are needed, you only need to change it here.
When overrideScope is core, it applies to everything by default; otherwise, overrideScope needs to match the key above.
[
{
"match": {
"model": "chat-base",
"overrideScope": "core"
},
"modelConfig": {
"generateContentConfig": {
"temperature": 0.5
}
}
},
{
"match": {
"model": "chat-base",
"overrideScope": "loop-detection"
},
"modelConfig": {
"generateContentConfig": {
"temperature": 0
}
}
}
]
customAliases #
Parameter Setting: modelConfigs.customAliases
Github PR: https://github.com/google-gemini/gemini-cli/pull/13546
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Supports custom aliases, but the priority is higher than aliases.
context #
fileName #
Parameter Setting: context.fileName
Github PR: https://github.com/google-gemini/gemini-cli/pull/1001
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Used to configure the file list for context memory.
includeDirectories #
Parameter Setting: context.includeDirectories
Github PR: https://github.com/google-gemini/gemini-cli/pull/5354
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Directories other than the workspace that the model can see, which can be understood as supporting multiple workspaces.
loadMemoryFromIncludeDirectories #
Parameter Setting: context.includeDirectories
Github PR: https://github.com/google-gemini/gemini-cli/pull/5354
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Supports loading the GEMINI.md file in .gemini from different workspace directories.
fileFiltering #
Parameter Setting:
context.fileFiltering.respectGitIgnorecontext.fileFiltering.respectGeminiIgnorecontext.fileFiltering.enableRecursiveFileSearchcontext.fileFiltering.disableFuzzySearch
Github PR: https://github.com/google-gemini/gemini-cli/pull/1290 / https://github.com/google-gemini/gemini-cli/pull/3727 / https://github.com/google-gemini/gemini-cli/pull/6087 /
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Whether to filter .gitignore and .geminiignore during file search, whether to support recursive retrieval, and whether to disable fuzzy retrieval.
respectGitIgnore and respectGeminiIgnore might slow down startup!
tools #
sandbox #
Parameter Setting: tools.sandbox
Github PR: https://github.com/google-gemini/gemini-cli/pull/1154
Supported in CLI/A2A-Server: Only CLI supported, A2A-server unavailable
Function Description:
Whether to enable the sandbox or the sandbox image.
shell #
Parameter Setting:
tools.shell.enableInteractiveShelltools.shell.pager(ignored)tools.shell.showColor(ignored)tools.shell.inactivityTimeout
Github PR: https://github.com/google-gemini/gemini-cli/pull/10661 / https://github.com/google-gemini/gemini-cli/pull/13531
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
enableInteractiveShell determines which shell mode to use. If enabled, it uses node-pty; if not enabled, it uses child_process.spawn or child_process.exec.
inactivityTimeout is the maximum time for no output from a shell command, default is 5 minutes.
autoAccept #
Parameter Setting: tools.autoAccept
Github PR: https://github.com/google-gemini/gemini-cli/pull/6665
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported (Official notes state server-side agent might not need sandbox association)
Function Description:
Auto-accept, divided into three modes: Default, *AUTO_EDIT, YOLO.
A2A-server currently does not support configuring *AUTO_EDIT.
core #
Parameter Setting: tools.core
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Used to limit built-in tools.
allowed #
Parameter Setting: tools.allowed
Github PR: https://github.com/google-gemini/gemini-cli/pull/6453
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Allows a set of tools to skip user confirmation. For shell commands, you can finely control whether to confirm specific commands, e.g., [“run_shell_command(git)”, “run_shell_command(npm test)”].
exclude #
Parameter Setting: tools.exclude
Github PR: https://github.com/google-gemini/gemini-cli/pull/12728
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Used to exclude specific tools.
enableToolOutputTruncation #
Parameter Setting: tools.enableToolOutputTruncation
Github PR: https://github.com/google-gemini/gemini-cli/pull/8039
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
run_shell_command tool
Truncates tool output based on character count. The truncation threshold is the minimum of the truncateToolOutputThreshold parameter and the remaining context window (model’s token limit * 4 minus consumed tokens).
Math.min(
// Estimate remaining context window in characters (1 token ~= 4 chars).
4 *
(tokenLimit(this.model) - uiTelemetryService.getLastPromptTokenCount()),
this.truncateToolOutputThreshold,
)
truncateToolOutputThreshold #
Parameter Setting: tools.truncateToolOutputThreshold
Github PR: https://github.com/google-gemini/gemini-cli/pull/8039
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
run_shell_command tool
Threshold for truncating tool output characters.
truncateToolOutputLines #
Parameter Setting: tools.truncateToolOutputLines
Github PR: https://github.com/google-gemini/gemini-cli/pull/8039
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
run_shell_command tool
Threshold for truncating tool output lines.
enableMessageBusIntegration #
Parameter Setting: tools.enableMessageBusIntegration
Github PR: https://github.com/google-gemini/gemini-cli/issues/7231
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Whether to enable message bus integration. This MessageBus has roughly the following functions:
- It serves as the primary context for tool execution. During execution, tools have access to the message bus in addition to their input parameters, making it the ideal place to store or retrieve contextual information.
- The policy engine is integrated into the message bus, enabling integration of some policy rules.
- Such as whether to allow execution, deny execution, or ask the user.
- safety check rules.
- hook check rules.
enableHooks #
Parameter Setting: tools.enableHooks
Github PR: https://github.com/google-gemini/gemini-cli/issues/9097
Supported in CLI/A2A-Server: Only CLI supported, hook registration and execution only supported in CLI
Function Description:
enableMessageBusIntegration to be enabled first.
Allows hooks to intercept and interact with messages on the bus.
security #
blockGitExtensions #
Parameter Setting: security.blockGitExtensions
Github PR: https://github.com/google-gemini/gemini-cli/pull/12838
Supported in CLI/A2A-Server: Only CLI supported, A2A-server not supported
Function Description:
Blocks installing and loading extensions from git and github-release. Default supports four types: git, github-release, local, and link. Extensions here refer to gemini-cli extensions in ~/.gemini/extensions, which can be Mcp, hooks, memory context, etc.
Postscript #
There are other parameters like hooks, advanced, mcpServers, telemetry, etc., which I won’t go into detail here. If interested, you can check the official Gemini CLI documentation directly.


